Redashのクエリパラメータで実現するインタラクティブなデータ集計
はじめに
データベースのテーブルデータを集計する際、Redashを使うとDBとの接続やクエリの記述がすぐにできて非常に便利です。
そのRedashでクエリを作成する際によく使うクエリパラメータのトリックを紹介します。
集計粒度の選択
データを集計する際は、目的に応じて異なるカラムを使って集計したくなることがよくあります。
このとき、ベースになるクエリは1つだけ作り、その中で集計に使うカラムを自由に都度選択できるようにすると、似たようなクエリを沢山作成して管理する必要がなくなり非常に便利です。
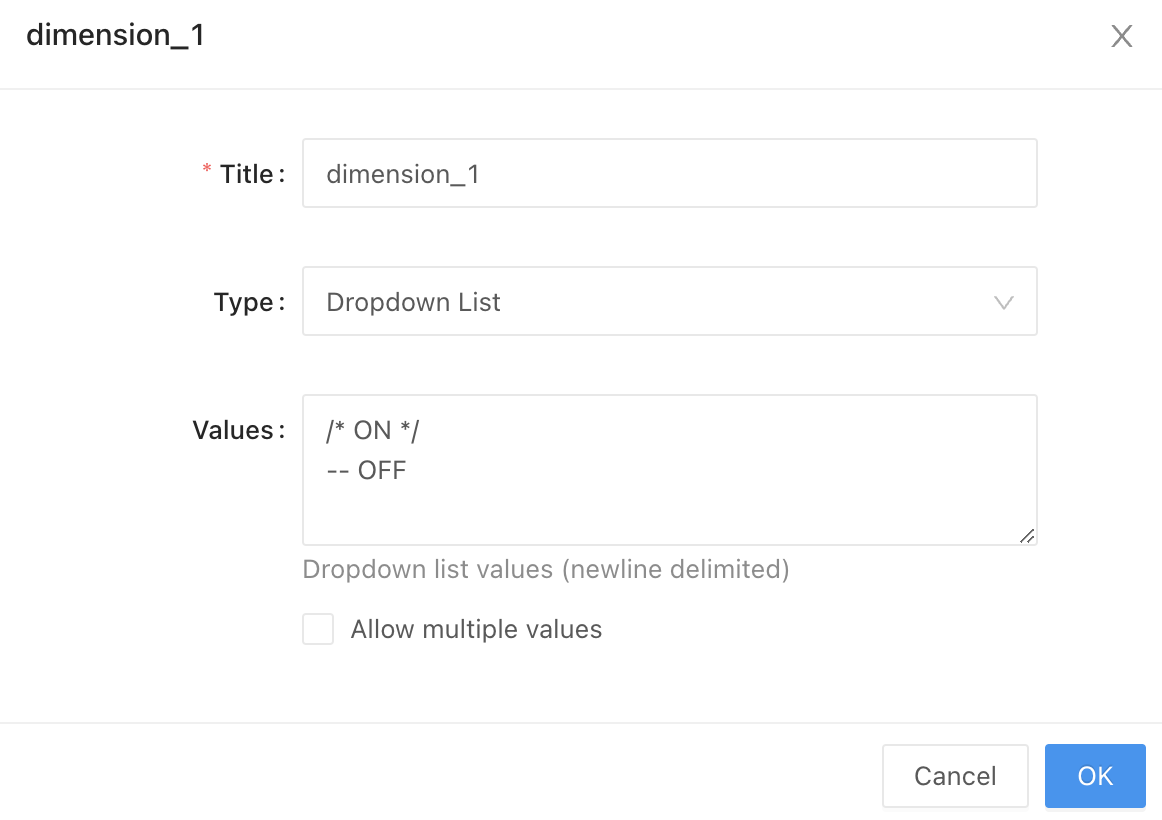
以下のようにカラム名の前にパラメータを配置し、そのパラメータでの入力は Dropdown List で /* ON */ -- OFF を選択する形式にします。
select common_key_1, {{ dimension_1 }}, dimension_1 {{ dimension_2 }}, dimension_2 , sum(value_1) , sum(value_2) from table_name group by common_key_1, {{ dimension_1 }}, dimension_1 {{ dimension_2 }}, dimension_2
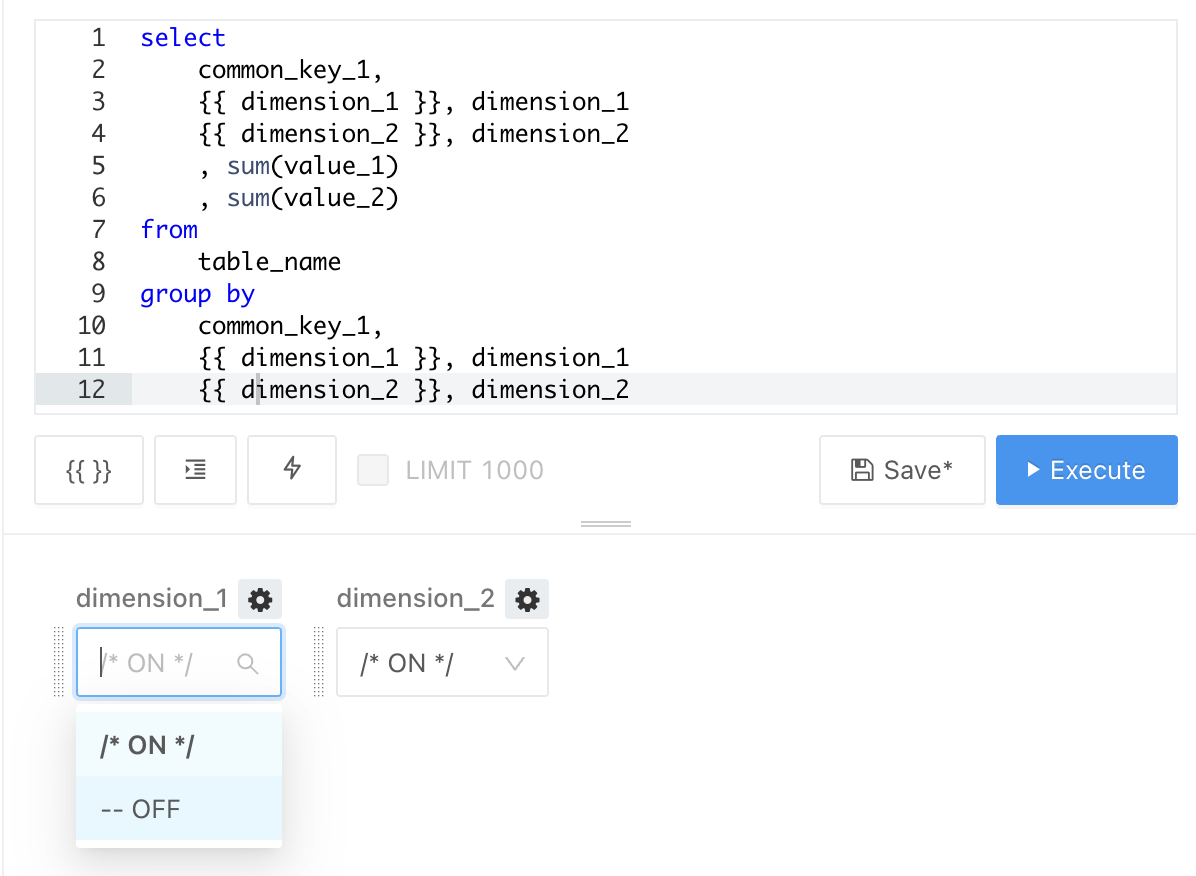
< 集計粒度を選択するクエリパラメータ
‐‐OFFを選択すると、行末まですべてコメントアウトされるため、パラメータの後ろにあるカラムは集計粒度として使われなくなります。/* ON */を選択すると、パラメータの後ろにあるカラムはコメントアウトされすに集計粒度として使われます。
パラメータで /* ON */ --OFFを選択したときに実際に発行されるクエリは以下のようなものです。
select common_key_1, -- OFF, dimension_1 /* ON */, dimension_2 , sum(value_1) , sum(value_2) from table_name group by common_key_1, -- OFF, dimension_1 /* ON */, dimension_2
条件指定の選択
同様のパラメータを使うことで、where句で条件指定をする/しないを選択できるようにもできます。
select dimension_1 , sum(value_1) , sum(value_2) from table_name where true {{ xxx_idの指定 }} and xxx_id in ({{ xxx_id(カンマ区切り) }})
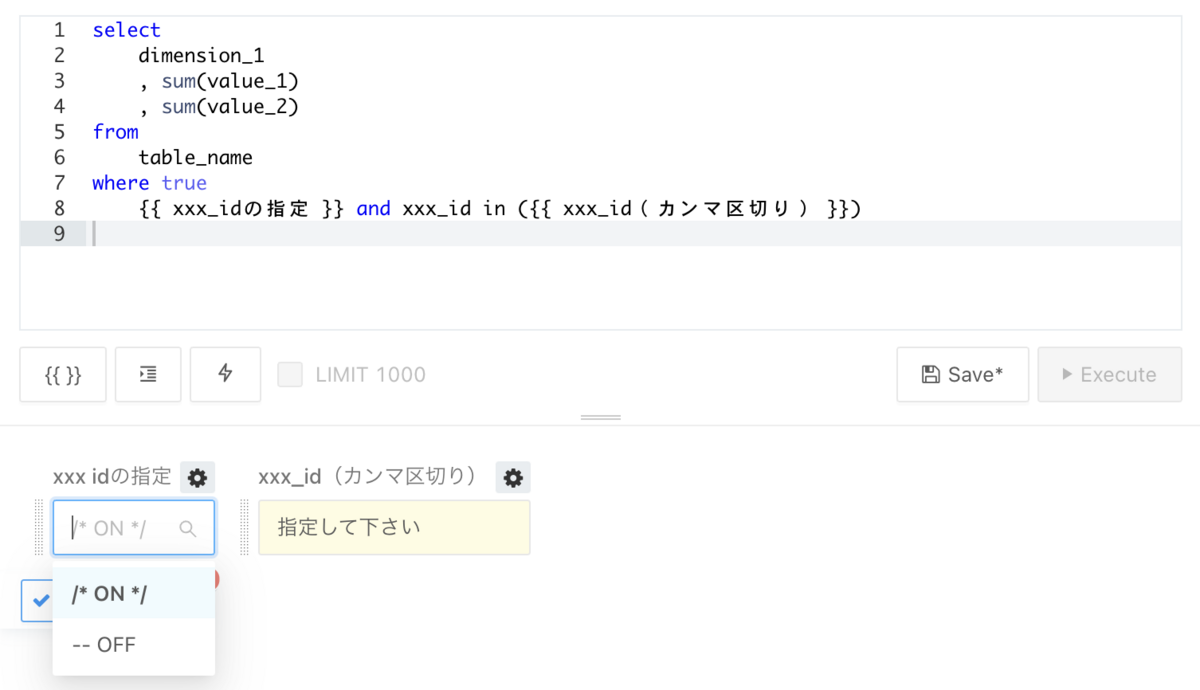
「xxx_idの指定」で‐‐OFF を選択すると、行末まですべてコメントアウトされるため、全レコードが集計されます
select dimension_1 , sum(value_1) , sum(value_2) from table_name where true --OFF and xxx_id in (指定して下さい)
「xxx_idの指定」で/* ON */ を選択すると、「xxx_id(カンマ区切り)」に値を入力することで、xxx_idが指定した値であるレコードだけが集計されます
select dimension_1 , sum(value_1) , sum(value_2) from table_name where true /* ON */ and xxx_id in (12, 34, 56)
最後に
Redashを使うと簡単にクエリを作成できる反面、クエリのクローンやコピペによって似たようなクエリがたくさん作成されてしまい、管理しづらくなることがあります。 そういった事態を防ぐ方策の1つとして、今回紹介したような方法が活用できそうです。
slackのメッセージを利用して出社時刻を可視化する
この記事はマイクロアドアドベントカレンダーの25日目の記事です。 qiita.com
はじめに
2021年のマイクロアドアドベントカレンダーのトリを飾るこの記事は、
また今年も一人でクリスマスを迎えている私がお送りいたします。
今年も残すところあと1週間。
マイクロアドでは、昨年の途中からリモートワーク体制へと移行して自宅勤務が基本となったため、今年の出社は週1回程度です。
緊急事態宣言中はその週1出社も任意となったため完全リモートでの勤務となりました。
ちなみに、私の自宅では布団から作業机までの距離が約1mしかないため、起床して2歩ほど歩くだけで勤務を開始できるという珠玉の環境が整っております。
さて、リモートワーク体制になって以降、マイクロアドのシステム開発部では毎日勤務を開始するときと勤務を終えるときにslackへ連絡することになっています。
勤怠連絡専用のチャンネルが用意してあって、メンバーそれぞれが毎朝「おはようございます」とか「お先に失礼します」とか書いているわけです。
そのslackチャンネルからAPIを使って「おはようございます」みたいなメッセージを集めてくれば、部内のメンバーがそのメッセージを投稿した時刻も手に入れることができます。
その時刻はほぼ出社時刻と同じであるとみなせるので、これさえ集めてくれば出社時刻の分析が可能となります。
というわけで、この記事では開発部の出社時刻のデータを収集して可視化し、どんな様子か一緒に眺めてみたいと思います。
準備
環境は Python 3.9.7 を使います。
まずは利用するライブラリをimportしておきます。
import pickle import re from datetime import datetime, timedelta, date, time from typing import List from jpholiday import is_holiday import pandas as pd import numpy as np import matplotlib.pyplot as plt import ptitprince as pt from tabulate import tabulate from slack import WebClient from time import sleep
slackからメッセージを収集する
チャンネル名と検索期間を指定して、slack APIを使ってメッセージを収集していきます。
ここでは以下のような条件で収集します。
- メッセージの収集先: #勤怠連絡
- 期間:2021年1月1日〜12月24日
# -------------------- # パラメータの設定 # -------------------- # クレデンシャル(自分のトークンを用意して使いましょう) SLACK_BOT_TOKEN = 'xoxp-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' # 検索条件 channel = {'id': 'XXXXXXXXX', 'name':'勤怠連絡'} # slackチャンネルのidと名前 date_start = date(year=2021, month=1, day=1) date_end = date(year=2021, month=12, day=24)
pythonからslack APIを呼んでメッセージを取得します。
conversations_historyというAPIで取得できるのはスレッドルートのメッセージだけで、スレッド内のリプライは取得できません。
そこで conversations_repliesというAPIを使ってリプライメッセージも収集します。
どちらのAPIも一定時間あたりの実行回数に上限があるので、適宜sleepして頻度を調整しています。
# -------------------- # slackメッセージの取得 # -------------------- class SlackMessageFetcher: def __init__(self, client: WebClient): self.__client = client def fetch(self, channel: dict, date_start: date, date_end: date) -> List[dict]: conversations = self.__get_conversations_in_channel( channel_id=channel['id'], # date_startの0時0分0秒 oldest_timestamp=datetime(year=date_start.year, month=date_start.month, day=date_start.day).timestamp(), # date_endの翌日の0時0分0秒 latest_timestamp=(datetime(year=date_end.year, month=date_end.month, day=date_end.day) + timedelta(days=1)).timestamp() ) return conversations # チャンネルごとにメッセージを取得 def __get_conversations_in_channel(self, channel_id: str, oldest_timestamp=None, latest_timestamp=None): next_cursor = '' conversations_list = [] while True: response_conversations = self.__client.conversations_history( channel=channel_id, limit=200, oldest=oldest_timestamp, latest=latest_timestamp, cursor=next_cursor ) conversations_list.extend(response_conversations['messages']) if response_conversations['has_more']: next_cursor = response_conversations['response_metadata']['next_cursor'] sleep(1) else: break return conversations_list class SlackThreadMessageFetcher: def __init__(self, client: WebClient): self.__client = client def fetch(self, channel: dict, messages) -> List[dict]: replies_list = [] for message in messages: if message.get("reply_count"): replies = self.__get_replies_in_message(channel_id=channel['id'], ts=message['ts']) replies_list.extend(replies) sleep(1.2) return replies_list def __get_replies_in_message(self, channel_id: str, ts: str) -> List[dict]: replies_list = [] next_cursor = '' while True: replies = self.__client.conversations_replies( channel=channel_id, ts=ts, limit=200, cursor=next_cursor ) replies_list.extend(replies['messages']) if replies['has_more']: next_cursor = replies['response_metadata']['next_cursor'] sleep(1) else: break return replies_list client = WebClient(token=SLACK_BOT_TOKEN) messages = SlackMessageFetcher(client).fetch(channel=channel, date_start=date_start, date_end=date_end) replies = SlackThreadMessageFetcher(client).fetch(channel=channel, messages=messages)
取得したメッセージはとりあえずファイルに保存しておきます。
# 取得したメッセージを保存 with open("messages.pickle", "wb") as f: pickle.dump(messages, f) with open("replies.pickle", "wb") as f: pickle.dump(replies, f) # 保存したメッセージをロード with open("messages.pickle", "rb") as f: messages = pickle.load(f) with open("replies.pickle", "rb") as f: replies = pickle.load(f)
messagesとrepliesを合わせれば、チャンネル内のメッセージがすべて取得できたことになります。
ただし、replies(スレッド内のリプライを取得した結果)の中には、スレッドルートのメッセージも含まれるので、単純に2つを混ぜてしまうと一部メッセージが重複してしまいます。
「messagesのうちリプライがないメッセージ」と「replies」を合わせることで重複なく全メッセージを取得できます。
# メッセージの重複を排除 no_reply_messages = [message for message in messages if message.get("reply_count") is None] all_messages = no_reply_messages + replies
これでslackメッセージが取得できました。
slackメッセージから朝の挨拶だけ抜き出す
分析対象となる出勤時のslackメッセージの抽出方法を定義しておきます
時間帯を平日6:00〜13:00に絞ったのは、業務や私用などのために発生した早朝出勤・早退・午後出勤などの影響を取り除くためです。
たまに発生するイレギュラーイベントは今回の分析のスコープには含みません。
あくまでも平常時の出勤時刻を見ていきたいということです。
APIが返してくれるメッセージには様々な情報が含まれるので、それを使って特定の条件に合致するものだけ抽出できます。
# -------------------- # 出勤時の挨拶メッセージの抽出 # -------------------- def is_good_morning(message: dict, keyword: re.Pattern): timestamp = datetime.fromtimestamp(float(message.get("ts"))) if message.get("username") is not None or message.get("user") is None: # bot投稿 return False if message.get("bot_id") == 'XXXXXXXXXX': # botによってはIDを指定して除外したほうがいいケースもある return False if is_holiday(timestamp): # 祝日 return False if timestamp.weekday() >= 5: # 土日 return False if not time(hour=6, minute=0, second=0) < timestamp.time() < time(hour=13, minute=0, second=0): return False if not keyword.search(message.get("text")): # 「おはようございます」みたいな文字列 return False return True greeting_text = r'おはようございます|おはヨーグルト|おはよウナギ' greeting = re.compile(greeting_text) greeting_messages = [message for message in all_messages if is_good_morning(message=message, keyword=greeting)]
データを整形する
分析などで使いやすいように、pandasのデータフレームに整形します。
タイムスタンプをもとに、曜日、月、日にち、時刻、10分刻みの時刻、などのカラムを追加します。
10分刻みの時刻は可視化するときに利用します。
# -------------------- # 分析用にデータ整形 # -------------------- df = pd.DataFrame(greeting_messages)[["ts", "user", "text"]] # タイムスタンプ df["ts"] = df["ts"].apply(lambda x: datetime.fromtimestamp(int(float(x)))) # 曜日 df["weekday"] = df["ts"].apply(lambda x: x.weekday()) # 月 df["month"] = df["ts"].apply(lambda x: x.month) # 日にち df["day"] = df["ts"].apply(lambda x: x.day) # 時刻 df["time"] = df["ts"].apply(lambda x: x.time()) # 時刻10分刻み df["time_rounded"] = df["time"].apply(lambda x: x.replace(minute=(x.minute//10)*10, second=0)) # 時刻を秒に変換 df["seconds"] = df["time"].apply(lambda x: timedelta(hours=x.hour, minutes=x.minute, seconds=x.second).total_seconds()) # 秒から角度に変換 df["radian"] = df["seconds"].apply(lambda s: 2*np.pi*s / (60*60*24)) # 角度_10分刻み df["radian_rounded"] = df["seconds"].apply(lambda s: 2*np.pi*(s-s % 600) / (60*60*24)) # 角度_10分刻み_午前6時〜午後6時 df["radian_rounded_clock"] = df["radian_rounded"].apply(lambda r: 2*r - np.pi) # 並び替え df = df.sort_values(['month', 'day']).reset_index(drop=True)
中身はこんな感じになります
print(tabulate(df.head(), headers='keys', tablefmt='psql')) +----+---------------------+-----------+----------------------+-----------+---------+-------+----------+----------------+-----------+----------+------------------+------------------------+ | | ts | user | text | weekday | month | day | time | time_rounded | seconds | radian | radian_rounded | radian_rounded_clock | |----+---------------------+-----------+----------------------+-----------+---------+-------+----------+----------------+-----------+----------+------------------+------------------------| | 0 | 2021-01-04 07:54:41 | XXXXXXXXX | おはようございます | 0 | 1 | 4 | 07:54:41 | 07:50:00 | 28481 | 2.0712 | 2.05076 | 0.959931 | | 1 | 2021-01-04 08:57:03 | XXXXXXXXX | おはようございます | 0 | 1 | 4 | 08:57:03 | 08:50:00 | 32223 | 2.34332 | 2.31256 | 1.48353 | | 2 | 2021-01-04 09:02:08 | XXXXXXXXX | おはようございます! | 0 | 1 | 4 | 09:02:08 | 09:00:00 | 32528 | 2.3655 | 2.35619 | 1.5708 | | 3 | 2021-01-04 09:15:25 | XXXXXXXXX | おはようございます | 0 | 1 | 4 | 09:15:25 | 09:10:00 | 33325 | 2.42346 | 2.39983 | 1.65806 | | 4 | 2021-01-04 09:18:34 | XXXXXXXXX | おはようございます | 0 | 1 | 4 | 09:18:34 | 09:10:00 | 33514 | 2.43721 | 2.39983 | 1.65806 | +----+---------------------+-----------+----------------------+-----------+---------+-------+----------+----------------+-----------+----------+------------------+------------------------+
時刻→角度への変換
時刻を角度(ラジアン)に変換したカラム df["radian"] を追加していますが、これは24時間を2πとしたときにそれぞれの時刻が何ラジアンになるのかを表します。
たとえば、6時ならπ/2、12時なら π、18時なら3/2 * πといった値になります。
時刻に対する演算は意外と厄介なもので、方向統計学的な手法が必要となります。
平均や中央値のような素朴に思える統計量ですら、迂闊には計算できません。その際にこのような変換が必要になってきます。
(後々の分析で使えるようにと思ってカラムに追加しましたが、記事執筆の時間切れのため、本稿ではこの値を使った分析までできませんでした。この辺はまた別の機会に)
また、df["radian_rounded_clock"] というカラムの意味ですが、
これは6時 <= time < 18時の範囲が 0 <= radian_rounded_clock < 2*π の角度の範囲に対応するよう変換しています。
今回の記事では6時から13時までのメッセージに限定して抽出していますが、この変換をすることで時刻の分布を時計のようなレイアウトのグラフに表示することが出来ます。
出勤時刻の分布を可視化する
全体的な出勤時刻の分布
はい、ここから可視化してきます。
まずは2021年のシステム開発部全体の出勤時刻の分布を円形のヒストグラムで確認します。*1
円形のヒストグラムは時計と同じレイアウトにできるので直感的に理解しやすいはずです。
radii = df.groupby("radian_rounded_clock").size() theta = np.array(radii.index.tolist()) colors = plt.cm.viridis(radii / 1000.) width = (2*np.pi) / (60*60*12 / 600) # binの太さは10分ずつ ax = plt.subplot(projection='polar') ax.bar(theta, radii, width=width, bottom=0.0, color=colors) ax.set_theta_direction(-1) # 時計回り ax.set_theta_offset(np.deg2rad(-90)) ax.set_xticks(np.linspace(0, 2*np.pi, 12, endpoint=False)) ax.set_xticklabels(np.linspace(6, 18, 12, endpoint=False, dtype=int)) ax.set_yticks([]) # y軸削除 plt.show()

出勤時刻の分布はこのような感じになります。
1つのビンが10分間に対応していて、ビンの長さが頻度(データの件数)に対応します。
このグラフを眺めてみると、出勤頻度が一番高いのは朝の9時20〜30分ころのようですが、
10時〜11時頃に出勤する人も多いようです。
曜日別の出勤時刻の分布
では次に、出勤時刻の分布が曜日別にどのように違うのか見ていきます。
複数の分布を比べてみたいので、先程の円形ヒストグラムとは別のグラフであるRainCloudで可視化します。*2
def secs2time(secs: int, time_format="%H:%M"): m, seconds = divmod(secs, 60) hours, minutes = divmod(m, 60) time_obj = time(hour=hours, minute=minutes, second=seconds) if time_format is None: return time_obj else: return time_obj.strftime("%H:%M") def time_linspace(start: time, end: time, steps: int) -> np.array: start_secs = timedelta(hours=start.hour, minutes=start.minute, seconds=start.second).total_seconds() end_secs = timedelta(hours=end.hour, minutes=end.minute, seconds=end.second).total_seconds() delta = (end_secs- start_secs) / (steps-1) increments = range(0, steps) * np.array([delta]*steps) secs2time_vec = np.vectorize(secs2time) return secs2time_vec((start_secs + increments).astype(int)) def show_rain_cloud(df: pd.DataFrame, type: str, orient: str= "v", pointplot=False): if type not in ["month", "weekday", None]: raise ValueError if orient not in ["h", "v"]: raise ValueError time_ticks = np.linspace(2*np.pi*6/24, 2*np.pi*13/24, 8, endpoint=True) time_ticklabels = time_linspace(time(hour=6), time(hour=13), 8) weekday_labels = ["Mon", "Tue", "Wed", "Thu", "Fri"] ax = pt.RainCloud(x=type, y="radian", data=df, orient=orient, pointplot=pointplot) if orient == "v": ax.set_yticks(time_ticks) ax.set_yticklabels(time_ticklabels) ax.set_ylabel("time") if type == "weekday": ax.set_xticklabels(weekday_labels) else: ax.set_xticks(time_ticks) ax.set_xticklabels(time_ticklabels) ax.set_xlabel("time") if type == "weekday": ax.set_yticklabels(weekday_labels) plt.tight_layout() plt.show() show_rain_cloud(df, "weekday")

各グラフに対して、
- 小さな点1つひとつはデータポイント
- 山型のバイオリンプロットは密度推定
- 四角い箱は箱ひげ図
になっています。
出勤のピークは曜日で大した違いはなさそうですが、
金曜日は早い時間帯に出勤するケースが少しだけ多いようです。
月別の出勤時刻の分布
最後に、出勤時刻の分布が月別にどのように違うのか見ていきます。
show_rain_cloud(df, "month")

若干見にくいですが、がんばって目を凝らしましょう。
2021年の前半は出勤時刻のピークが9:30分ころに立っているのがわかりますが、
後半になるにつれてそのピークが丸くなだらかになっている(=出勤のタイミングがバラけてる)のがわかります。
最後に
今回はslackから出勤時刻のデータを取得して可視化するところまでの流れを確認しました。
結構な分量になったので、ちゃんとした分析はまたの機会に回します。
それでは、メリークリスマス&良いお年を。